

Build Your Own Computer Walmart
Walmart Global Tech is the software technology arm of Walmart and is in charge of building, owning and deploying solutions to solve the complex challenges that the e-commerce and store (brick & mortar) aspects of the business face today. The group that I work with creates applications that live in Walmart's private cloud to be used by our US Store associates. One of the most interesting challenges we face is to build applications that can handle the immense scale and 24/7 availability requirements that are expected from nearly 5000 US stores of the world's No 1 retailer.
I had the privilege of leading a team to deliver a React Native iPad application that was backed by Spring Boot services on the Walmart Cloud. The iPad application collects information from users and sends that information to the downstream services. Although the idea is simple and usage is expected to be low, there is a lot of functional as well as non-functional complexity under the surface. The application must be available 24/7/365, never lose data in any situation, and even perform when the network is unavailable
In this post, I will discuss some of the issues we addressed with the aid of some Java based code examples.
System Architecture
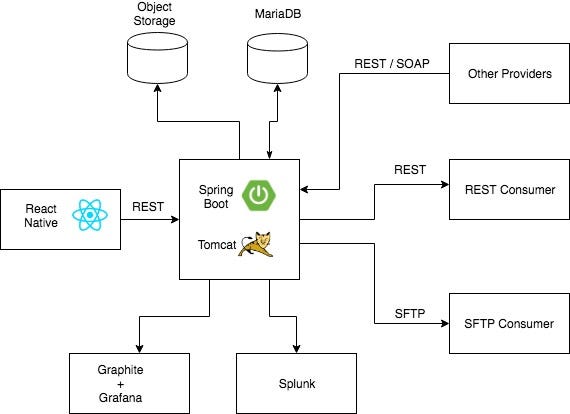
The service utilizes Spring Boot and deploys a war artifact to Tomcat running in Walmart's internal cloud. It exposes REST APIs that are accessed by the UI running on iOS platform using React Native. The APIs create metadata resources that are persisted in MariaDB, while large attachments are stored in object storage. Some additional information needed by the UI is fetched from other providers in the diagram. There are two downstream consumers — one that provides a REST API and other that is basically an SFTP server. Logs are sent to Splunk and metrics are sent to Graphite to be viewed in Grafana dashboards.
The service is deployed in two data centers in active-active mode. The MariaDB is actually a Galera cluster of database servers with the data replicated in multiple data centers. The object storage clusters are also deployed in multiple data centers. Both MariaDB and Object Storage are managed by others teams in Walmart so my team does not have to know about their implementation or deal with the operational issues involved in running them.
As I mentioned in my previous post, the throughput expected from this system is low, on the order of less than 10 TPS. So the load is not significant. Also a temporary outage is acceptable, however the system is expected to never lose data.
Technical Deep Dive
Let's begin our deep dive into the technical details of the application that most helped with scaling the application starting from the Pilot stores and taking it to the US Chain. I'm going to present a bunch of topics and show you how we addressed some of the issues related to each along with code snippets and diagrams where appropriate.
High Availability
It is important to note that while a service outage can happen, the app is still available to the user. A user of the mobile app does not necessarily have to be concerned if the outage is just temporary such as a restart of the back-end services during a scheduled upgrade.
Much of this level of availability can be achieved using a simple load-balanced, stateless REST service design.
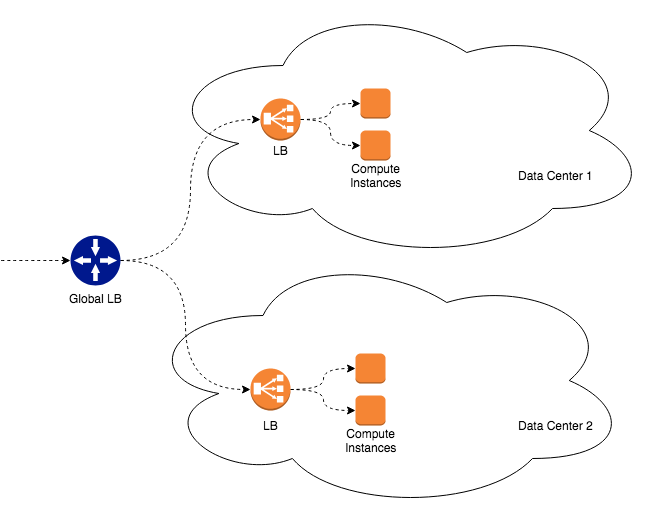
The Global Load Balancer forwards requests to two data centers based on proximity. A load balancer in each data center round-robins the request to the nodes behind it. Both data centers are active for the application cluster.
The MariaDB setup is a bit different:
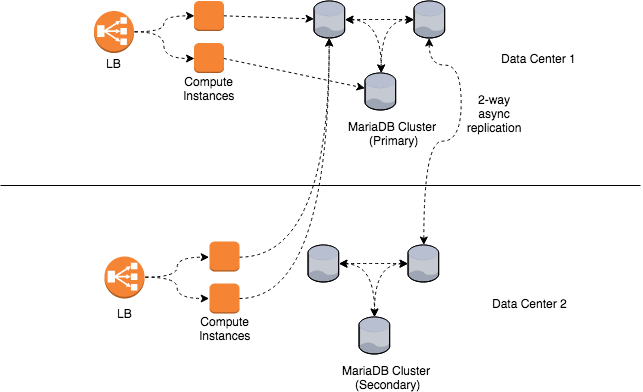
The services in both data centers point to a single primary MariaDB cluster in one of the data centers which will failover to a secondary cluster in other data centers. Yes, this causes additional unwanted latency going across data centers which you can see from the diagram above. However that additional latency is perfectly acceptable for this particular application. If a disaster does occur, the application will experience a temporary outage as the application is switched over to the other data center. Also, the UI is capable of surviving a temporary service outage that may result if the primary cluster goes down. This kind of setup is easier to maintain and works well for our requirements. I probably would not have chosen this if the application requirements were any stricter.
The database clusters in each data center use a technology called Galera which utilizes a certification based multi-master synchronous replication. Since the Galera cluster is synchronous it does affect latency on writes. However it provides the high consistency needed for the application. There is asynchronous two way cross data center replication that ensures that data is replicated. There could be a replication lag which has to be dealt with if a disaster does occur. A lag would mean that although data isn't actually lost because a data center is temporarily down, the data that was in transit is not in the other data center that survives the disaster. This scenario seems unacceptable, however the downside risk is limited since the actual volume of data that might be affected is very small.
The Object Storage setup looks like this:
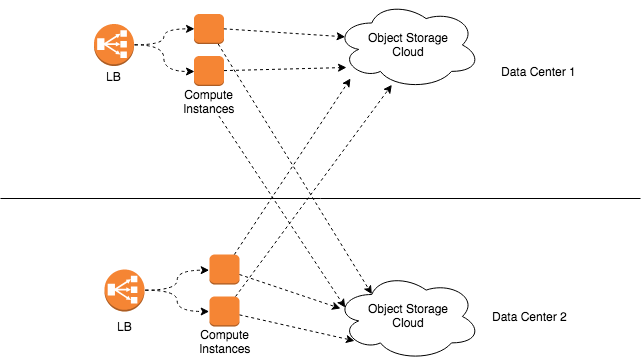
The object storage writes are performed to the storage cloud in one of the data centers and not replicated to the other data center. Reads are performed against both data centers and there are no updates. This design allows just a single copy of the object to exist at any given time in either data center. Most of the object storage operations coming from the UI are writes. The reads are performed asynchronously when a user ends their session so we do not have to be concerned with the additional latency of searching both data centers for an object. Also there are no updates, so that greatly simplifies things. We do not have to be concerned about consistency of the object across data centers.
If there is outage in one of the storage clusters, the application loses access to the objects stored there until it comes back online. However new requests go to the other data centers. So a temporary outage occurs for transactions in progress, but new transactions go elsewhere and the application continues to function. This situation is acceptable since the UI is capable of handling temporary outages.
During the expansion of the initial set of stores to all stores in the chain, we encountered situations where the object storage cloud in one data center was affected by an upgrade. Since we had already factored in the possibility of this happening we were able to sail through unaffected.
Idempotency for POSTs
RFC 2616 says that methods GET, PUT and DELETE should be idempotent. That means aside from error or expiration issues, the side-effects for multiple requests are the same as for a single request. So if I issue 1 GET request or 2 or 3 of them with the same request headers and body, the net result is going to be the exactly the same. The same idea applies to PUT and DELETE requests. Now this is not always true in reality — it depends on how you have implemented your REST controllers but if you do not follow the RFC then your implementation is just non-conforming.
Why is this a good thing? Let me explain:
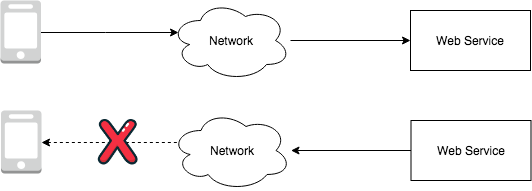
If the network does not drop packets or do anything insidious, the request makes it all the way to the service and a response is received by the client. But let's say we have a regular old unreliable network, which means connections could be dropped at intermediate gateways or edge routers, timeouts could result from heavy packet losses over bad Wifi networks, etc. If the request is lost before it makes it to the service, the client can timeout or detect a lost socket connection and try the request again. If the request is tried again, it could succeed and we have nothing to fear. If the response from the server is lost before it makes it to the client, we can only assume one of two things has happened — either the desired result has been achieved in the service or not. But the client has no way to know — it simply retries the request. If the method is not idempotent, the second request sent by the client could have unexpected consequences.
So that explains why idempotency is a good thing. But if you read RFC 2616 you'll notice that they left out the POST method. This method is intended to have side-effects since the intention was to use it to create new objects. While this makes sense for most applications, it turned out to be that the application we were building could not handle empty objects created when a POST was retried due to network issues. We ended up solving this issue using a correlation-id header in every POST request. The correlation-id is just a unique UUID generated by the client. Although different clients can generate the same UUID, the chance that this could happen in conjunction with network retries is very low.
The idempotency for POSTs was implemented using the HandlerInterceptorAdapter class in Spring MVC. This allows us to process request headers in a preHandle method before the Controller method is invoked, while a postHandle method allows us to cache Location headers in the responses after the Controller method has been exited.
There are still race conditions in this code that surface with smaller timeout values. It is possible for a second request to enter the preHandle method and get past the 301 check before the Location header from the first request gets cached in the postHandle method. This can however be addressed by a slight modification to reject the second request with the same correlation Id if the first one was previously received but has not finished processing.
This isn't perfect since we're assuming the cache is immediately consistent and that the first request will be complete at some point. These assumptions are on top of the assumption that UUIDs will be unique.
Nevertheless, these assumptions are good enough to handle network-error related retries in most applications properly. We did not see several retry attempts coming from the UI in the stores during the initial pilot rollout to a limited set of stores. But as we expanded the footprint towards chain we started seeing more network-error related retries.
Concurrency Considerations
This application has two downstream consumers — a REST consumer and an SFTP consumer. The REST consumer is expected to provide a reference number for the information submitted by the user operating the UI. That reference number is displayed to the user. The request going to the SFTP consumer also needs this reference number but the user doesn't need anything from the SFTP consumer.
Since we have a user waiting for something to come back from a downstream service, we don't want them to be waiting very long. A typical SLA in such situations is really not more than a few seconds.
Our initial prototype before we piloted the application in a single store did something very simple here. It used a single thread to process all requests from the UI. This guarantees that the SFTP consumer's request always gets processed after the REST consumer's request. However it forces all requests to be processed serially, so the next request from the UI will wait for the previous one to complete. The response time for any request increases with the total number of requests.
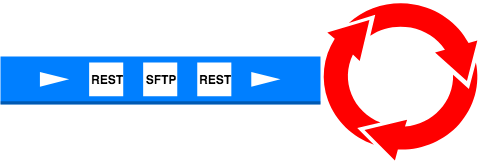
This isn't ideal but it works well when there's only one request coming from a single deployment to a single store. So it allowed us to not worry about concurrency issues when we needed to take our application to a single pilot store. The need to get feedback about the app in production was more important that worrying about rolling it out to hundreds or thousands of stores.
So once we deployed this implementation to a single store, we improved the concurrency for the REST consumer by separating the concurrency concerns of the reference number retrieval from the concerns for the SFTP consumer. We did this by having separate thread pools for the REST consumer and SFTP consumer.

Have you spotted the problem with the code above? There is no way to guarantee that the SFTP consumer requests get processed before the REST consumer requests.
So how can we do this in Java? One way to do it would be to generate the request for the SFTP consumer after the response from the REST consumer has been processed.
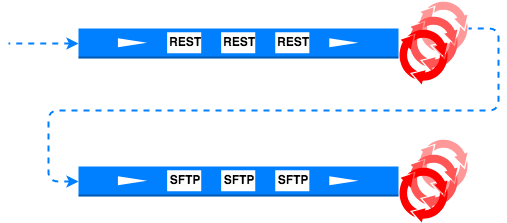
The issue with this is that there is coupling between the code that handles both of the downstream consumers. One could handle this by using the Event Bus pattern. Just use an application event bus where the first consumer returns a response and the service that handles that response puts out an event on the bus. Any other service such as the SFTP handling service sees this event and creates the necessary request for that service.
Event buses are generally speaking a good thing to decouple your application logic in this manner. Using this pattern is not trivial because the events and their consumers have to be registered and you need to version and manage the schema of the events generated.
However there is another simpler way to directly address the needs of the system using a CompleteableFuture. This provides a neat way in java to create a dependency between two asynchronous tasks that need to be chained. The SFTP task in this case needs to run after the REST consumer task. Both need to run in separate thread pools but one needs to be triggered after the other completes.
There is still an issue with the code above related to exception handling. When an exception occurs while a thread is executing some code, the JVM passes control to a default uncaught exception handler if one is registered for that thread. If not, the default behavior is to print the stack trace to the system error output. Basically the exception just got swallowed here because we didn't do appropriate logging in the code we wrote. But CompleteableFuture provides the exceptionally method that allows one to register an exception handler for precisely this reason. However this should not be used in lieu of proper exception handling in your code.
Audit Logs
We started out building an app given the business requirements — initial goal to get something in a pilot program. However along the way realized that once app is running safely in pilot we need information on exactly what failures happened, which transactions were affected and which stores were affected so we could assess the impact of failures quickly and provide support to the business. We would also need this information to let the business determine if it wanted to expand the current set of stores further along the way to "Chain". Basically we needed data to make go/no-go decisions based on hard facts. To do that we needed daily reports of successes and failures of the app in the field.
We determined that having an audit log of business events that were generated as the app was used would satisfy our criteria. Since application logs are best-effort and maintained only for a limited length of time by the logging service team, it didn't satisfy our non-functional requirements. Also application logs capture a lot of noise and it would be easy to miss a business event when looking at a large set of logs.
However, we would also need to maintain a separate audit log implementation within our infrastructure. We decided to create the audit logs as a log table in our MariaDb database since it offered the save availability guarantees as the rest of the data. Since the volume of events is not very great, we didn't need an implementation that provided very high write throughput and huge storage capabilities.
We built an API around the audit log similar to the one below:
In order to use the API above, one could simply create a Postman Collection that would query these APIs daily or build a utility such as a command line utility in Python or Java. We chose to build a utility with a quick UI using Swing because we thought the types of queries we would want to do were not well defined at the beginning of our rollout to the US Chain. The Swing utility allowed anyone to start using our audit logs to produce a daily report of user sessions that experienced failures. This was very useful to our business stakeholders.
Log Filtering
Our application deals with highly sensitive data. This means that we need to make sure that information that goes out into the application logs does not mistakenly contain sensitive data like social security numbers, etc. You may also need to escape HTML characters to prevent what are known as Log Forging attacks. This is easily accomplished by using the interceptor pattern with your logging framework.
With Logback you can use a TurboFilter to do the interception. This intercepts every log message before it gets written out by Logback. The idea is that you do some processing to replace sensitive keywords and also escape HTML keywords etc. This is definitely adding overhead to the work that needs to be done by the logging system so it needs to be done judiciously. The code that I present here is not optimized for higher throughput so you may expect to see additional penalties when running this under high load.
Logback creates an instance of your TurboFilter class and uses it to intercept all logs. Using this method you can sanitize your log messages and write your new sanitized version out to the log. You could also just drop messages that have sensitive data. However you might lose context when looking at the logs and trying to troubleshoot issues because a log message with sensitive information got dropped.
Because the TurboFilter is instantiated by Logback itself and not Spring, you lose the ability to inject a bean managed by Spring. So be careful when you use this technique in a spring boot project.
I must note here that the above code only filters logs coming from your own source code package. However there may be places in dependent libraries where turning on trace level logging could compromise your application's privacy requirements. In the case of the Apache HTTP client the logger named org.apache.http.wire can dump unencrypted binary data to the logs if running at TRACE level. This is something you need to be aware of for your specific application. You may want to restrict the log level for these libraries.
Tracing
Any real world application that is used by more than just a handful of users has its challenges with regard to operations and maintenance. The ability to look at application logs and determine how a users data has been handled by your application in the event of an issue reported in the field is a very desirable feature.
In order to trace what has happened to requests coming in from a specific user the application will need to dump enough context about the incoming requests along with application or audit logs to allow any operator in production to be able to determine what has happened to a users data. The last thing you want is un-traceability where it is very difficult or not possible to determine if the application still has the users data in a recoverable format if an error arises at runtime.
There are multiple tools available to do this. The tool that we opted for which proved to be the most useful was the MDC logging feature that is available with the Logback library. This basically uses thread local variables in order to keep some context variables which can then be printed out with each log by applying the correct log pattern.
Here's a simple example using the following code:
But you won't actually see anything new in the logs unless you actually modify your log pattern to include these variables explicitly:
This is nice but there are issues. First, how do you get the context to be passed between thread boundaries? It is very likely that your application offloads work from the Controller thread to some Executor Service threads to perform work in a non-blocking fashion. In that case you would want to always apply the MDC variables before any code is executed in a Thread and then clear those automatically after execution. Here's an example of how to do this if you're not using Spring for task execution:
Here's how you use it in a very simple example:
Spring's task execution API however has a much better way to decorate tasks before they are executed. If you're using Spring's ThreadPoolTaskExecutor, you can set a org.springframework.core.task.TaskDecorator to apply the same decorator logic above to any task executed in the thread pool.
The second issue is the source of your context variables. In the application we built, the context came from the request itself and this is probably true in the case of most applications. You could save the MDC variables in your REST Controller methods by extracting them from the body of the request first. However this leads to a tightly coupled brittle solution that is hard to maintain. The approach we took was for the client (React UI) to append application specific headers to every outgoing request that would provide the correct context variables for every call. We then chose to use a Servlet Filter to capture and insert these variables into the MDC context.
The code above basically provided us with a complete view of the flow of data in the service for any user in the field that was using our app. Because of the MDC context that is present in each log message it is now possible to do searches in our logs that allow us to troubleshoot issues very quickly.
IMHO this is the non-functional feature besides the audit log that has proved to be the most valuable when operating the application starting with the pilot program with a few stores and expanding the store footprint slowly all the way to the US Chain of ~5000 stores. It enables root cause analysis and business impact determination for the technical team which is what our stakeholders desire to know when there are major issues like outages or resource exhaustion.
Testing integration with mocked services
Most applications in production experience some small probability of network errors and timeouts. When a deployment has a small number of users the rate of failures due to network errors is usually very low. However as the number of users increases the number of failures due to network errors and network related timeouts increases.
It is useful to capture test scenarios such as these between parts of your application that communicate over the network. Regression testing of this kind helps isolate issues before they are discovered in production. Frequently such issues are only found after the user base has been significantly scaled.
How does one test for such things during a regression test? There are a few approaches that have been used for this:
- Unit test with mock: One could test this behavior in a unit test by mocking a response from the downstream service and testing the expectation from the class under test. The results here will guarantee the behavior of the class under test, but not the behavior of the product at runtime.
- Integration test with mock: This is basically where you stand up your own application in an integration type environment as well as a separate mocked downstream service using a framework such as Wiremock or something you've written yourself. The mocked service simply provides canned responses to specific requests. You can use this to send back HTTP 500s, cause timeouts, drop responses etc. Wiremock is particularly useful because of its ability to simulate faults in response to a request.
- Proxy with custom error injection: This method also requires that you standup an integration type environment with your application and a copy of the downstream service. However you use a proxy that lies in between your application and the downstream service. The proxy could be something you write yourself. This idea is useful for simulating errors or timeouts in scenarios that are difficult to mock. Basically you are inserting chaos into the behavior of the downstream service which allows you to test all sorts of scenarios including random error injection that attempts to simulate actual production behavior.
We use Wiremock extensively in our integration tests to simulate faults resulting from either errors in the network or in the downstream application. Here's an example of how to do this with Wiremock:
This story is adapted from a post that originally appeared here
Build Your Own Computer Walmart
Source: https://medium.com/walmartglobaltech/building-a-24-7-365-walmart-scale-java-application-12cb7e58df9c
Posted by: wilbankssmill1985.blogspot.com
0 Response to "Build Your Own Computer Walmart"
Post a Comment